Verilog实现简单的卷积计算
简要说明
使用Verilog实现核大小为3*3的简单卷积。
计算作用的图像来自MNIST数据集(自行查阅),图像大小为28*28,像素为8bit,长这样:

图像的像素点很少可以直接存入BRAM中:图像按行顺序展开为一行784个的8bit数,然后用coe文件存入Vivado提供的ROM中。卷积计算的结果为26*26大小的数组,按行展开存入RAM中。
注:因为只是简单尝试实现卷积,没有过于考虑速度和资源消耗
模块设计
rom
用于存储图像,使用BRAM IP核
在Vivado中操作:
- 选择类型为单端口ROM
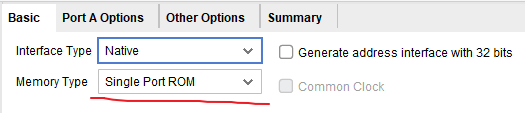
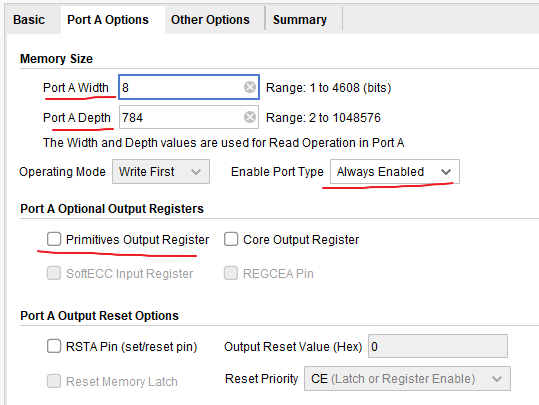
- 设置数据位宽和地址深度,设置总是使能
- 注意:不使用输出寄存器。输出寄存器会导致时许偏移,详细自行查阅
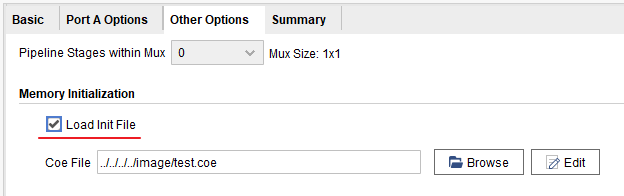
- 设置coe文件初始化ROM
打包一下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
module rom (
input in_clk,
input [9:0] in_rom_addr,
output [7:0] out_rom_data
);
rom_gen_0 u_rom1 (
.clka(in_clk),
.addra(in_rom_addr),
.douta(out_rom_data)
);
endmodule
image_read
从存储图像的ROM中读取用于卷积计算的9个像素点
端口配置如下:
1 | module image_read( |
in_rom_data和out_rom_addr为与ROM数据口和地址口连接的端口,
9个像素读取完成时,out_data_valid置为高,9个像素从out_pixels送出,
卷积模块读取像素后进行计算时,in_conv_cal被置为高,下一轮读取ROM开始,
当整张图像都被读取完成,out_image_end置为高,模块不再与ROM交互。
image_read模块设计的难处在于怎么从被展开为一行的784个像素中读取需要的9个像素,这9个像素位于不同的行和列。
设计的思想:用行和列坐标表示3*3像素数组的左上角坐标,根据该读取第几个像素来计算需要读取的像素在0~783的位置。
挑重点讲:
主要的信号为:
1
2
3
4reg [3:0] r_read_cnt; // 0~8
reg [4:0] r_read_ptr_x; // 0~25
reg [7:0] r_read_ptr_y; // 0~25*7
reg [9:0] r_rom_addr; // 0~783r_read_cnt从0计数到9,记录当前读取到第几个像素,r_read_ptr_x和r_read_ptr_y记录前述左上角的坐标,很显然这个坐标只需要从(0,0)到(25,25)即可,所以r_read_ptr_x的大小为025。但是如果25,那么计算坐标时需要将r_read_ptr_y也是0r_read_ptr_y与28相乘,秉持尽量不使用乘号的原则换个思路:
r_read_ptr_y可以每次加28,此时表示的位置是784个像素中一行像素的起始位置,但是r_read_ptr_y就需要存储大至25*28大小的数,注意到28是4的倍数,就是说r_read_ptr_y如果存储28的倍数,那么低两位为00,所以可以隐含,r_read_ptr_y每次加7即可综上,ROM地址
r_rom_addr的计算可以表示如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14always @(*) begin
case (r_read_cnt)
'd0 : r_rom_addr = r_read_ptr_x + (r_read_ptr_y << 2);
'd1 : r_rom_addr = r_read_ptr_x + (r_read_ptr_y << 2) + 'd1;
'd2 : r_rom_addr = r_read_ptr_x + (r_read_ptr_y << 2) + 'd2;
'd3 : r_rom_addr = r_read_ptr_x + (r_read_ptr_y << 2) + 'd28;
'd4 : r_rom_addr = r_read_ptr_x + (r_read_ptr_y << 2) + 'd29;
'd5 : r_rom_addr = r_read_ptr_x + (r_read_ptr_y << 2) + 'd30;
'd6 : r_rom_addr = r_read_ptr_x + (r_read_ptr_y << 2) + 'd56;
'd7 : r_rom_addr = r_read_ptr_x + (r_read_ptr_y << 2) + 'd57;
'd8 : r_rom_addr = r_read_ptr_x + (r_read_ptr_y << 2) + 'd58;
default: r_rom_addr = r_read_ptr_x + (r_read_ptr_y << 2);
endcase
end
PE
PE是计算卷积的单元,3*3的卷积一共有9个PE单元,PE单元的卷积参数可以单独配置。
PE单元实现的功能是A*B,A为像素数据,B为卷积参数,
A*B的实现使用Vivado提供的DSP IP核:
- 选择计算指令为A*B
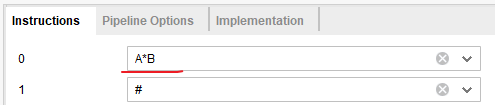
不加入中间寄存器,在后续模块的设计时会使用寄存器存储结果
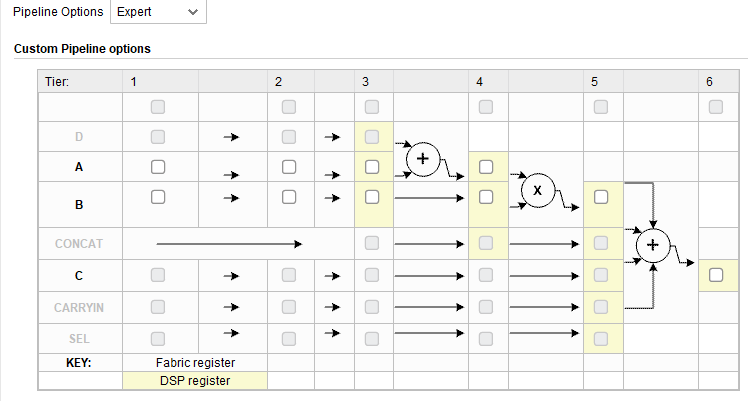
设置输入输出的位宽
A(像素数据)设置为9位,因为DSP处理的是有符号数,8bit的像素为无符号数,需要高位补0后计算,
B(卷积参数)为5位;P(输出结果)的位宽配置为14位
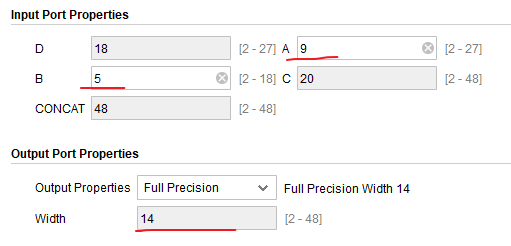
代码示例:
1 |
|
conv
conv模块实例化PE模块,读取image_read的9个像素后协调PE模块进行计算,
计算的思路:9个像素分别送入各个PE模块,再将这些结果累加
注意:DSP IP核支持A*B+C的运算,但是仿真时结果一直不正确,并且发现A+C的运算也不正确,所以没有用DSP算加法,问题的原因未知,DSP IP的版本是xilinx.com:ip:dsp_macro:1.0
端口定义:
1 | module conv( |
ram
RAM中存储卷积计算后的26*26个结果,位宽为14bit,与conv计算的结果对应
- 选择类型为单端口RAM
- 配置位宽等参数
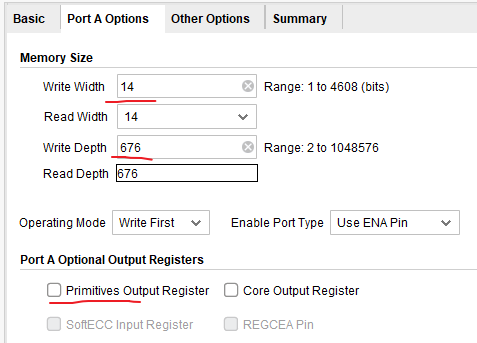
打包一下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
module ram(
input in_clk,
input [9:0] in_ram_addr,
input [13:0] in_ram_data,
input in_ram_en,
input in_ram_we
);
ram_gen_0 u_ram (
.clka(in_clk),
.addra(in_ram_addr),
.dina(in_ram_data),
.ena(in_ram_en),
.wea(in_ram_we),
.douta()
);
endmodule
注意:RAM只用于存储数据,没有读取,综合时可能会被Vivado优化
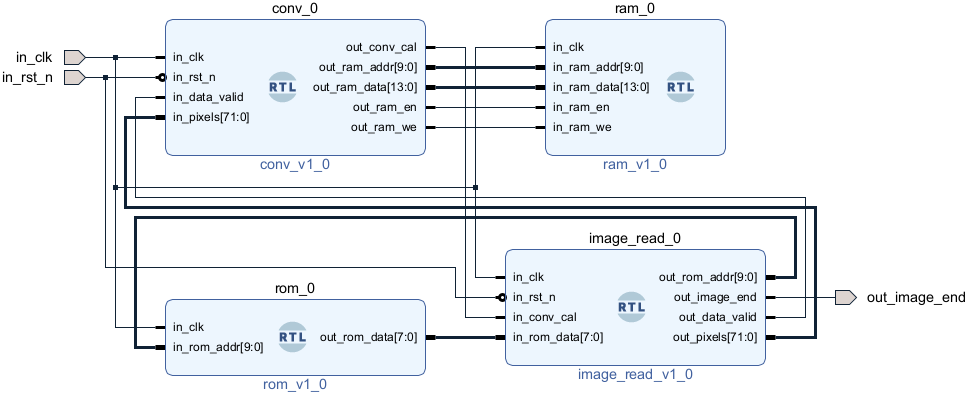
顶层设计
使用Block Design添加模块并连线:
仿真
在Vivado进行一个简单的仿真
特别注意:DPS IP的仿真文件是VHDL语言的,需要把仿真语言设置为Mixed才能仿真
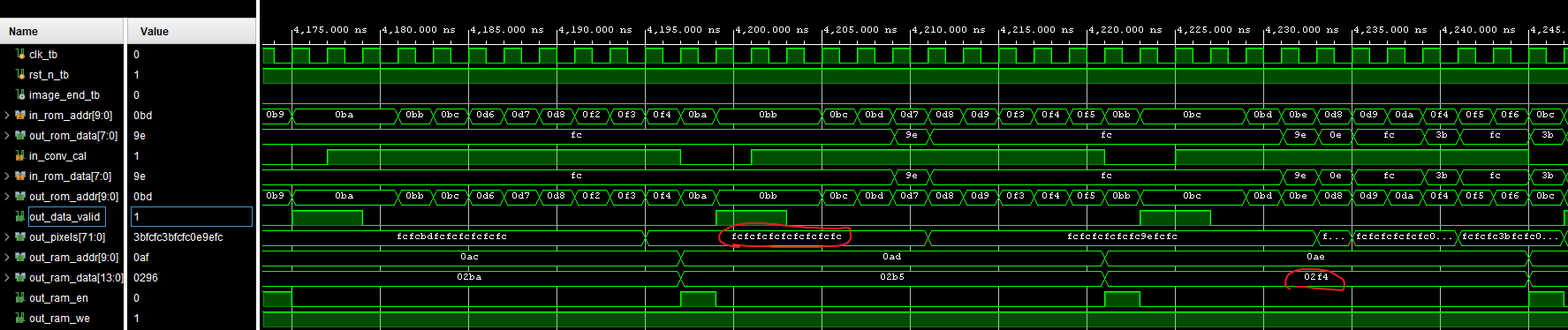
从ROM中读出的9个像素为FC FC FC FC FC FC FC FC FC(十六进制),卷积核为[[1, -1, 1], [1, -1, 1], [1, -1, 1]]
卷积计算的结果为2F4,正好为FC的三倍,结果正确。可以看到,计算一次卷积大概需要11个时钟,处理速度的瓶颈在于读取ROM数据和累加计算
在仿真时把写入RAM的数据存入txt文本,可以看到正好26*26=676个数